

LFM2-2.6B-Exp: Pure Reinforcement Learning for on device LFM2 models
The frontier of artificial intelligence is rapidly moving to edge computing, demanding models that are both powerful and exceptionally efficient. The introduction of LFM2-2.6B-Exp: Pure Reinforcement Learning for on device LFM2 models represents a major leap forward in this domain. This experimental checkpoint, built upon the LFM2-2.6B architecture, showcases a novel training regimen that prioritizes behavior driven optimization. Instead of relying on a final supervised fine tuning stage, it uses a pure reinforcement learning approach to directly enhance instruction following, knowledge tasks, and mathematical reasoning.
As a result, this compact 3B class model delivers remarkable performance improvements tailored for on device assistants and agentic systems. Because it maintains an efficient hybrid stack of convolutional layers and grouped query attention, it balances a small footprint with a large context window. This article explores the architecture, training methodology, and benchmark results that set a new standard for capable, deployable AI.
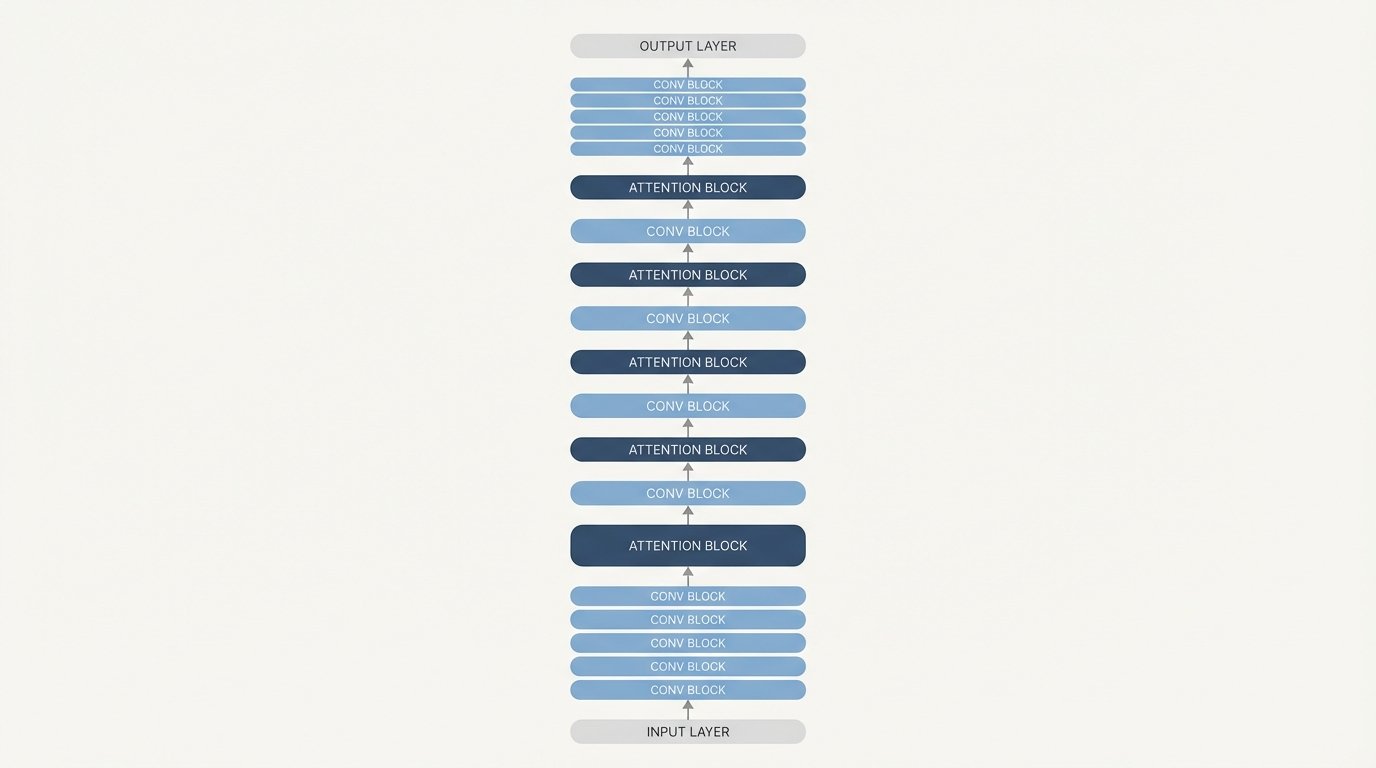
A simplified visual of the LFM2 hybrid stack, showing the interleaved convolution and attention blocks that enable its on device efficiency.
Architecture and the Reinforcement Learning Edge
The performance of LFM2-2.6B-Exp is rooted in a highly efficient hybrid architecture and a novel training methodology. This combination allows the model to deliver strong results within a compact 3B parameter budget, making it ideal for on device applications where resources are constrained. The design carefully balances computational cost with representational power, ensuring both speed and accuracy.
The Hybrid Stack in LFM2-2.6B-Exp: Pure Reinforcement Learning for on device LFM2 models
LFM2-2.6B-Exp builds upon a unique hybrid neural stack that intelligently combines convolutional layers with attention mechanisms. This structure is designed to process information efficiently across its 30 layers. As a result, the model captures both local patterns and global context without the overhead of traditional transformer architectures. The architecture remains unchanged from the LFM2-2.6B base model.
Key architectural components include:
- 10 Double Gated Short Range LIV Convolution Blocks: These 22 convolutional layers handle local feature extraction and token mixing. Because they operate on shorter sequences, they significantly reduce computational demands compared to full self attention.
- 6 Grouped Query Attention Blocks: These 8 attention layers are responsible for capturing long range dependencies and aggregating global context. Grouped query attention is a more efficient variant that lowers memory usage and speeds up inference.
- Generous Context and Vocabulary: The model maintains a 32,768 token context length and a 65,536 token vocabulary. Therefore, it can process long documents and diverse multilingual inputs effectively, all while running on bf16 precision.
The Pure Reinforcement Learning Training Method
What truly sets LFM2-2.6B-Exp apart is its training regimen. It employs a pure reinforcement learning approach in its final phase, forgoing a conventional supervised fine tuning (SFT) warm up. This method directly optimizes the model’s behavior using reward signals. Consequently, the training hones its ability to follow complex instructions, perform mathematical reasoning, and use tools without an intermediate distillation step.
This behavior first optimization has several advantages:
- It directly aligns the model with desired outcomes and user preferences.
- Training extends from simple instruction following to more complex knowledge oriented prompts.
- It even incorporates a small amount of tool use, preparing the model for agentic workflows.
Dynamic Reasoning with Think Tokens
Furthermore, the LFM2-2.6B line, including this experimental version, enables dynamic hybrid reasoning through special “think tokens.” When the model encounters these tokens, it can perform intermediate computational steps internally before producing a final answer. This mechanism is particularly effective for improving performance on complex or multilingual tasks that require multi step thought processes.
To provide a clear overview of the LFM2 family, the table below compares key specifications and performance metrics across the different model sizes. As a result, readers can quickly assess the trade-offs between parameter count, architecture, and benchmark results.
| Model | Parameter Count | Layers (Conv / Attn) | Architecture Details | Training Budget | Precision | Context Length | Language Mix | GSM8K | IFEval | IFBench Score |
|---|---|---|---|---|---|---|---|---|---|---|
| LFM2-350M | 350M | Not Disclosed | Not Disclosed | 10T Tokens | bf16 | 32,768 | ~75% Eng, 20% Multi, 5% Code | Not Reported | Not Reported | Not Reported |
| LFM2-700M | 700M | Not Disclosed | Not Disclosed | 10T Tokens | bf16 | 32,768 | ~75% Eng, 20% Multi, 5% Code | Not Reported | Not Reported | Not Reported |
| LFM2-1.2B | 1.2B | Not Disclosed | Not Disclosed | 10T Tokens | bf16 | 32,768 | ~75% Eng, 20% Multi, 5% Code | Not Reported | Not Reported | Not Reported |
| LFM2-2.6B | 2.6B | 30 (22 / 8) | 10 LIV Conv Blocks / 6 GQA Blocks | 10T Tokens | bf16 | 32,768 | ~75% Eng, 20% Multi, 5% Code | 82.41% | 79.56% | Strong Baseline |
| LFM2-2.6B-Exp | 2.6B | 30 (22 / 8) | 10 LIV Conv Blocks / 6 GQA Blocks | Pure RL Phase | bf16 | 32,768 | ~75% Eng, 20% Multi, 5% Code | Not Reported | Not Reported | Surpasses DeepSeek R1-0528 |
Notes:
- The language pretraining mix includes English, Arabic, Chinese, French, German, Japanese, Korean, and Spanish.
- The LFM2-2.6B-Exp model is an experimental checkpoint that builds on the LFM2-2.6B base with a final pure reinforcement learning phase. Therefore, its architecture is identical, but its behavior is further optimized.
- All models in the 2.6B line support dynamic hybrid reasoning via think tokens and expose a ChatML-like template for tool use.
Benchmark Performance and On Device Deployment
The true measure of a foundation model lies in its performance and practicality. LFM2-2.6B-Exp excels in both areas, delivering impressive benchmark results while maintaining a design optimized for real world, on device deployment. This balance makes it a compelling choice for developers building the next generation of edge AI applications.
Surpassing Larger Models on Key Benchmarks
The pure reinforcement learning approach has yielded significant gains, allowing LFM2-2.6B-Exp to outperform much larger models. While the base LFM2-2.6B model already sets a high standard, the experimental checkpoint pushes the boundaries of what a 3B parameter model can achieve.
Key benchmark highlights include:
- IFBench Leadership: On the main headline metric, IFBench, LFM2-2.6B-Exp surpasses DeepSeek R1-0528, a model reportedly 263 times larger in parameter count. This demonstrates the power of behavior first optimization.
- Strong Foundational Scores: The underlying LFM2-2.6B architecture achieves an impressive 82.41% on GSM8K for mathematical reasoning and 79.56% on IFEval for instruction following.
The On Device Advantage of LFM2-2.6B-Exp: Pure Reinforcement Learning for on device LFM2 models
Beyond benchmarks, LFM2-2.6B-Exp is engineered from the ground up for on device use. Its compact size and efficient architecture translate into tangible benefits for deploying AI on hardware with limited resources.
Practical deployment advantages include:
- Low Latency: The hybrid stack with its mix of convolution and grouped query attention blocks minimizes computational load, resulting in faster inference times.
- Agentic Capabilities: Native tool use tokens and a ChatML like template allow the model to execute tasks and interact with external systems directly on device, with tool calls encoded as clean JSON.
- Advanced Reasoning: Special think tokens enable dynamic, multi step reasoning, allowing the model to tackle complex problems without needing to call a more powerful cloud based model.
- Open and Accessible: With open weights released on Hugging Face under the LFM Open License v1.0, developers have maximum flexibility. Furthermore, it supports a wide range of runtimes, including Transformers, vLLM, llama.cpp GGUF, and ONNXRuntime.
Conclusion: The Future of Efficient, On Device AI
LFM2-2.6B-Exp is more than just an experimental checkpoint; it is a powerful statement about the future of foundation models. It proves that a compact, 3B parameter model can achieve remarkable performance, even surpassing competitors hundreds of times its size. The key lies in its innovative architecture and, most importantly, its pure reinforcement learning training regimen. As a result, this model delivers behavior first optimization that translates directly to superior instruction following, reasoning, and tool use capabilities right at the edge.
This shift towards smaller, more efficient models is critical for the next wave of AI applications. For businesses looking to leverage this cutting edge technology, the challenge lies in practical implementation. This is where EMP0 comes in. At EMP0, we specialize in building AI driven sales and marketing automation solutions that deliver measurable outcomes. We believe in the power of deployable intelligence, using automation and data driven workflows to integrate powerful models like LFM2-2.6B-Exp into real world business processes. Whether it is for on device assistants, dynamic content generation, or structured data extraction, we provide the expertise to turn state of the art AI into a competitive advantage.
Explore how we can help you build the future of your business.
Find us online:
- Blog: https://articles.emp0.com
- n8n Creator Profile: https://n8n.io/creators/jay-emp0
Frequently Asked Questions (FAQs)
What is LFM2-2.6B-Exp and why is it significant for on-device AI?
LFM2-2.6B-Exp is an experimental AI model with 2.6 billion parameters, specifically designed for high performance on devices like smartphones and laptops. Its importance comes from its ability to run complex tasks locally without relying on the cloud. Because it uses a pure reinforcement learning approach, it excels at instruction following and reasoning. As a result, it provides a powerful yet compact solution for developers creating on-device assistants, agentic systems, and retrieval augmented generation (RAG) applications. Its small footprint and advanced capabilities make it a key player in the future of edge AI.
What does ‘pure reinforcement learning’ mean in this context?
Pure reinforcement learning refers to the final training phase that optimizes the model’s behavior directly using reward signals, instead of a traditional supervised fine tuning (SFT) step. This process starts with instruction following and extends to knowledge, math, and even tool use. Consequently, the model learns to generate outputs that are more aligned with user intent and practical utility. It skips an extra SFT warm up, making the alignment process more direct and focused on performance in real world scenarios.
How is the LFM2 architecture designed for efficiency?
The LFM2 architecture is built for efficiency using a hybrid stack. It contains 10 double gated short range LIV convolution blocks to process local information quickly and 6 grouped query attention blocks to handle long range context. This combination of 22 convolution and 8 attention layers reduces the computational and memory requirements compared to standard transformer models. Therefore, it can maintain a large 32,768 token context window and still achieve low latency on resource constrained hardware.
How does LFM2-2.6B-Exp’s performance compare to other models?
LFM2-2.6B-Exp demonstrates outstanding performance for its size. Its most notable achievement is on the IFBench benchmark, where it surpasses DeepSeek R1-0528, a model reported to be 263 times larger. This highlights the effectiveness of its specialized training. The base model, LFM2-2.6B, also has strong foundational scores, achieving 82.41% on the GSM8K math benchmark and 79.56% on the IFEval instruction following test. These results confirm its position as a top performer in the 3B class.
How can developers access and deploy this model?
The model is accessible to developers with open weights available on Hugging Face under the LFM Open License v1.0. For deployment, it supports a wide array of popular runtimes, including Transformers, vLLM, llama.cpp GGUF, and ONNXRuntime. This flexibility allows for easier integration into various applications. Developers can also leverage its native features like think tokens for complex reasoning and a ChatML like template for tool use to build sophisticated on device agents.