

V-JEPA: AI Learning Intuitive Physics from Videos
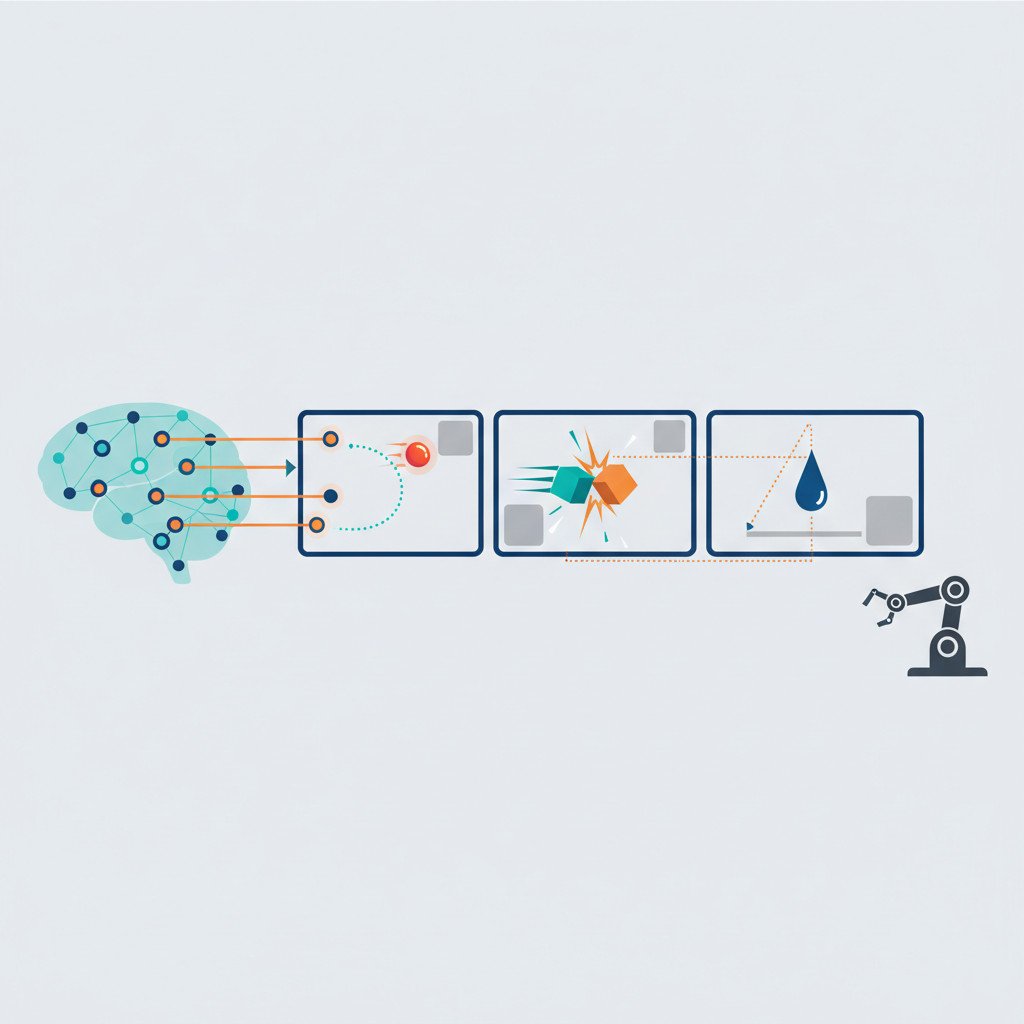
V-JEPA: AI learning intuitive physics from videos brings a bold new way to teach machines how objects behave. Rather than memorizing pixels, this Video Joint Embedding Predictive Architecture learns compact latent concepts from ordinary footage. Imagine an AI that watches a glass wobble on a table. It senses the momentum in slow motion and predicts whether it will tip.
Because V-JEPA masks portions of frames and predicts latent states, it discards unneeded detail and focuses on physical essence. As a result, the model grasps object permanence, gravity, collisions, and stable shapes. The scenes feel cinematic yet ordinary, and the model extracts laws from them like a scientist reading patterns in waves.
Training on millions of clips, V-JEPA builds a rough but useful memory of short video contexts. However, that memory spans only seconds, which limits long sequences. Still, this method lets robots learn with far less labeled data than end-to-end training. It opens a path toward robots that intuitively understand the world they act in.
V-JEPA: AI learning intuitive physics from videos
V-JEPA uses an elegant self supervised design to learn about motion and cause. It converts raw footage into compact latent signals. Then it predicts missing latent states instead of raw pixels. As a result, the model focuses on physical structure and ignores visual clutter.
Key architectural components
- Encoder one processes observed frames into embeddings. It compresses visual scenes into manageable vectors.
- Encoder two consumes masked target frames and encodes what the model should predict. This separation keeps training stable and efficient.
- Predictor maps the first encoder outputs to the second encoder outputs. The predictor learns to forecast future or hidden latent states.
How video input becomes physical intuition
- V-JEPA masks patches of frames rather than pixels. Because of this, the model must fill in whole spatial regions. That encourages reasoning about objects and dynamics.
- The system predicts in latent space. Therefore it avoids the noise of pixel level reconstruction and models core physical properties like velocity and contact.
- Training on large, ordinary video collections lets the model learn statistical regularities. As a result, it forms expectations about gravity, collisions, and object permanence.
What makes the approach unique
- It predicts embeddings not images. Thus it discards irrelevant texture and color detail.
- It separates encoding from prediction. This decoupling improves generalization and reduces sample needs for downstream tasks.
- It adapts to robotics with little labeled data. For example, the team fine tuned a predictor with about 60 hours of robot data to plan actions.
How V-JEPA differs from traditional models
- Traditional models often reconstruct pixels. They spend capacity modeling unimportant details.
- By contrast, V-JEPA models latent dynamics directly. Therefore it captures physics like a compact world model.
Further reading and sources
See Meta’s announcement for an overview at Meta’s Announcement. For technical details consult the V-JEPA 2 Preprint. For commentary on the release see InfoQ Commentary.
| Model | Learning approach | Accuracy / Benchmark | Input data | Scalability | Practical applications | Source |
|---|---|---|---|---|---|---|
| V-JEPA 2 | Latent-space prediction with masked frames and separate encoders | Very high on IntPhys (~98%); mixed on IntPhys 2 | Ordinary videos (22M clips); short temporal memory | Scales to 1.2B parameters; pretrain then fine-tune | Robotic planning; object permanence; manipulation | Source |
| Visual Interaction Networks (VIN) | Object-centric simulation with relation networks | Strong on simulated rigid-body benchmarks; good generalization | Simulated particle and rigid-body videos | Moderate model size; designed for simulation tasks | Physics simulation; prediction; few-shot generalization | Source |
| Neural Physics Engine (NPE) | Compositional object-based factorization with pairwise interaction nets | High accuracy in controlled 2D simulations; infers latent properties | Rendered simulations with known object states | Efficient for small object counts; research-scale | Simulation; property inference; model-based planning | Source |
| Video Pixel Networks (VPN) | Pixel-space autoregressive video modeling | High fidelity on synthetic benchmarks; poor generalization to clutter | Raw pixel videos; action-conditional frames | Computationally heavy; scales poorly to long or large videos | Action-conditional synthesis; robotic pushing experiments | Source |
Related keywords and semantic terms
- V-JEPA
- Video Joint Embedding Predictive Architecture
- latent representations
- encoder1
- encoder2
- predictor
- masking
- pixel-space models
- intuitive physics
- object permanence
Applications and future potentials of V-JEPA: AI learning intuitive physics from videos
V-JEPA: AI learning intuitive physics from videos promises real-world impact across tech and science. It learns compact latent dynamics from ordinary clips and applies them to perception and planning. Because it trains on videos, it transfers to systems that rely on rich visual input.
Key application areas
- Robotics
- Robots can plan manipulation and grasping with a learned world model. For example, Meta fine tuned a predictor with about 60 hours of robot data to plan actions. See the technical notes at technical notes for details.
- Autonomous vehicles
- Self-driving systems can use visual physics priors to predict other agents. Therefore they can better anticipate collisions and evasive maneuvers.
- Augmented reality and simulation
- AR systems can anchor virtual objects with realistic motion and collisions. As a result, AR experiences feel more stable and believable.
- Scientific discovery and observation
- Researchers can mine ordinary footage to infer physical laws and anomalies. Moreover, this reduces reliance on curated simulation datasets.
- Industrial automation
- Production lines gain robust visual models of object dynamics. Thus inspection and robotic sorting improve with less labeled data.
Future potentials and limits
V-JEPA could enable machines that reason like toddlers about objects and forces. However, current models retain only seconds of memory, which limits long horizon planning. Additionally, researchers note the need for better uncertainty encoding to handle ambiguous scenes. For commentary on the model’s strengths and limits see the Quanta Magazine overview.
With iterative research and larger context windows, V-JEPA style models may give robots and agents a robust physical intuition. Therefore these systems could reshape robotics, AR, simulation, and safety critical domains.
Conclusion
V-JEPA: AI learning intuitive physics from videos represents a meaningful step toward machines that reason about the physical world. It learns compact latent dynamics from ordinary video, and therefore it captures gravity, collisions, and object permanence without pixel reconstruction. As a result, V-JEPA reduces the labeled data needed for downstream robotics tasks.
Looking ahead, V-JEPA style models can power safer robots and smarter perception stacks. For example, robots can plan manipulations with a pretrained latent predictor, and autonomous vehicles can better anticipate collisions. However, current limits remain. The model stores only short temporal context and it needs improved uncertainty encoding. Nonetheless, iterative research will likely extend memory and robustness.
EMP0 brings practical value to this research era. Emp0 builds automation tools and deployable AI workers that scale client revenue by automating workflows and decision tasks. In addition, Emp0 integrates advanced models into production systems, turning research advances like V-JEPA into concrete business outcomes.
Connect with Emp0
Frequently Asked Questions (FAQs)
What is V-JEPA and how does it learn intuitive physics?
V-JEPA, or Video Joint Embedding Predictive Architecture, learns physical rules from ordinary video. It encodes frames into latent representations using two encoders and a predictor. The model masks target frame regions and predicts their latent states. Therefore it focuses on object motion, collisions, and object permanence. For technical details see this paper.
How does latent prediction differ from pixel reconstruction?
Pixel models reconstruct images and model noise. By contrast, V-JEPA predicts compact embeddings. As a result it ignores texture and color that do not matter. This improves robustness and reduces labeled data needs. Meta summarized the approach and applications at this article.
What are the main limitations today?
V-JEPA performs well on IntPhys but struggles on tougher IntPhys 2. Its short memory spans a few seconds. In addition, it lacks a full uncertainty encoding. However, researchers see clear paths to fix these gaps. Read commentary at this article.
Can V-JEPA power real robots and vehicles?
Yes. Teams fine tuned predictors with about 60 hours of robot data to plan actions. Therefore V-JEPA can speed up robotic manipulation and perception. Autonomous systems may use its physics priors to predict collisions and trajectories.
How does EMP0 help companies adopt these advances?
EMP0 builds automation tools and deployable AI workers that integrate advanced models. In addition, Emp0 helps convert research prototypes into production workflows. Visit EMP0’s website and our blog at this blog to learn about integrations and revenue multiplying AI workers. For n8n automation connectors see this page.
Related terms: V-JEPA, latent representations, encoder, predictor, masking, intuitive physics, object permanence.