

The Shifting Landscape of Artificial Intelligence
The artificial intelligence landscape is evolving at an unprecedented pace. New models are constantly emerging, each pushing the boundaries of what machines can achieve. This rapid innovation signals a major shift in the industry, moving beyond theoretical advancements to practical, high performance applications. A brilliant example of this trend is the new NousCoder-14B model, which showcases remarkable improvements in code generation. By using reinforcement learning with verifiable rewards, this model demonstrates a significant leap forward in creating reliable and efficient AI systems.
This development is not happening in a vacuum. It reflects broader transformations across the AI sector. We are witnessing a dynamic change in funding strategies, with a growing emphasis on sustainable and open source projects. Furthermore, the industry is increasingly prioritizing privacy first solutions, responding to a global demand for more secure and user centric AI. This article explores these interconnected trends, examining how groundbreaking models like NousCoder-14B are not just technological marvels but also catalysts for a new era in AI development. We will dive into the technical details, the financial underpinnings, and the ethical considerations shaping the future of artificial intelligence.
Technical Deep Dive: How NousCoder-14B Achieves State of the Art Performance
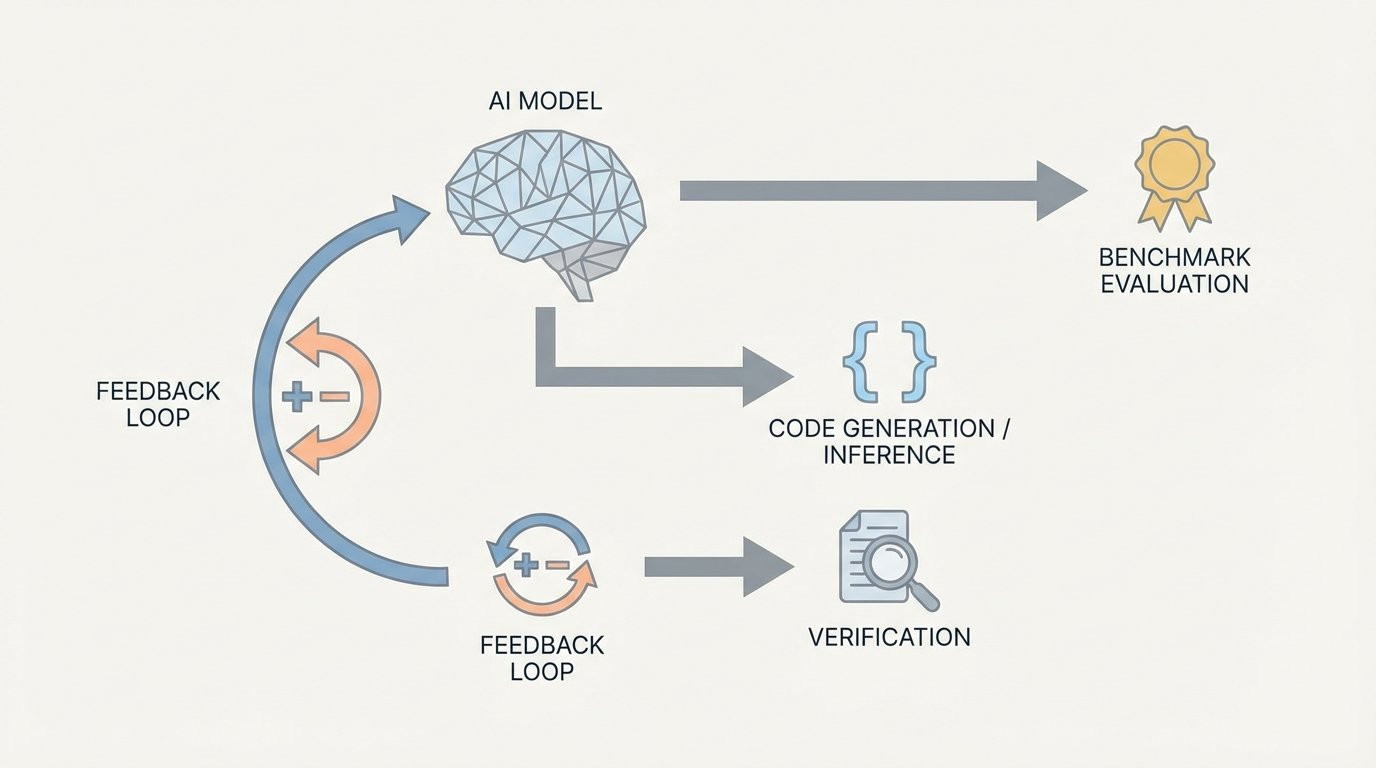
The remarkable performance of NousCoder-14B stems from its advanced training methodology. The model is post trained on the powerful Qwen3-14B foundation, leveraging its existing capabilities. However, the key innovation lies in the application of reinforcement learning with verifiable rewards. This approach fine tunes the model by providing clear, binary feedback on its code generation attempts. The system rewards correct solutions and penalizes incorrect ones, effectively teaching the model to produce more reliable and accurate code over time. This sophisticated training process is managed within the Atropos framework, a specialized environment designed for reinforcement learning.
Reinforcement Learning and Verifiable Rewards
The training environment for NousCoder-14B generates Python code for a wide range of problems. For each attempt, or rollout, the model receives a simple scalar reward. A reward of +1 is given if the generated code passes all test cases for a specific problem. Conversely, a reward of -1 is assigned if the code produces a wrong answer, exceeds a 15 second time limit, or uses more than 4 GB of memory. This clear feedback loop allows the model to quickly learn the characteristics of high quality code. The entire process is a reproducible, open stack, with the weights available under an Apache 2.0 license on Hugging Face, promoting transparency and further innovation.
Performance Benchmarks and Key Metrics
The results of this meticulous training are evident in the model’s exceptional performance on the LiveCodeBench v6 benchmark. The NousCoder-14B model sets a new standard for code generation, significantly outperforming its baseline.
- Pass@1 Score: It achieves a Pass@1 of 67.87% on 81,920 token contexts.
- Baseline Comparison: This represents a 7.08 percentage point improvement over the Qwen3-14B baseline of 60.79%.
- Training Scale: The model was trained on 24,000 verifiable coding problems.
- Hardware: The training utilized 48 NVIDIA B200 GPUs.
- Training Duration: The entire training process was completed in just 4 days.
Transparency and Community: Datasets, Licensing, and Reproducibility
The foundation of any great AI model is the data it learns from. NousCoder-14B was trained on a diverse set of verifiable code generation problems, ensuring the model learns from high quality and reliable sources. Each problem includes a reference implementation and multiple test cases, which is crucial for the verifiable rewards system used in training.
- TACO Verified: A collection of trusted and verified coding challenges.
- PrimeIntellect SYNTHETIC 1: A synthetic dataset designed to cover a wide range of programming tasks.
- LiveCodeBench Tasks: Problems created before July 31, 2024, from this live benchmark.
In a move that promotes collaboration, the model’s weights are accessible to everyone. This commitment to openness is a core principle of the project.
- License: The weights are released under the permissive Apache 2.0 license.
- Platform: They are available for download on the popular Hugging Face platform.
This open approach allows developers and researchers to build upon this work freely. Furthermore, the entire project is designed to be reproducible. The complete reinforcement learning pipeline code is available, creating a fully open stack. This level of transparency is vital for building trust within the AI community. It allows others to verify the results, understand the methodology, and contribute to future advancements.
Comparing Reinforcement Learning Strategies
Different reinforcement learning objectives were tested to find the most effective training strategy for NousCoder-14B. The following table compares the performance of Dynamic sAmpling Policy Optimization (DAPO), Group Sequence Policy Optimization (GSPO), and GSPO+ at different context lengths.
| RL Objective | Pass@1 at 81,920 Tokens | Pass@1 at 40,960 Tokens |
|---|---|---|
| DAPO | 67.87% | ~63% |
| GSPO | 66.26% | ~63% |
| GSPO+ | 66.52% | ~63% |
CONCLUSION
NousCoder-14B represents a significant milestone in the evolution of AI coding models. Its impressive benchmark achievements on LiveCodeBench v6 are a direct result of its innovative training, particularly the use of reinforcement learning with verifiable rewards. This model not only pushes the boundaries of performance but also champions a more transparent and collaborative future for AI. The decision to release the weights under an Apache 2.0 license, combined with a fully reproducible workflow, empowers the entire community to build upon this groundbreaking work. This open source philosophy is accelerating the pace of innovation and shaping a more accessible AI ecosystem.
At EMP0, we harness the power of such advanced AI to create tangible growth for our clients. We specialize in developing sophisticated AI and automation solutions tailored for sales and marketing. Our suite of proprietary tools, including a Content Engine, Marketing Funnel automation, and Sales Automation systems, is designed to drive efficiency and revenue. We also offer a Retargeting Bot and Revenue Predictions to give businesses a competitive edge. By deploying these powerful AI powered growth systems securely within our clients’ own infrastructure, we ensure both top tier performance and uncompromising data privacy. We are committed to leveraging the latest in AI to build the next generation of business solutions.
Website: emp0.com
Blog: articles.emp0.com
Twitter/X: @Emp0_com
Medium: medium.com/@jharilela
Frequently Asked Questions (FAQs)
What is NousCoder-14B?
NousCoder-14B is a highly advanced, 14 billion parameter artificial intelligence model specifically designed for code generation. It is built upon the Qwen3-14B foundation and has been fine-tuned using a sophisticated technique called reinforcement learning with verifiable rewards. This process significantly enhances its ability to produce accurate and functional Python code, making it a powerful tool for developers.
What is reinforcement learning with verifiable rewards?
This is the core training method that makes NousCoder-14B so effective. Instead of just learning from static examples, the model actively generates code and receives direct feedback. If the code works correctly (passes all tests), it gets a positive reward. If it fails, produces an error, or is too slow, it receives a negative reward. This continuous feedback loop teaches the model to improve its problem-solving abilities over time.
How does NousCoder-14B perform on benchmarks?
The model has demonstrated state-of-the-art performance. On the LiveCodeBench v6 benchmark, it achieved a Pass@1 score of 67.87% with a large 81,920 token context. This is a substantial improvement of over 7 percentage points compared to its baseline model, showcasing its superior code generation capabilities.
Is NousCoder-14B available for public use?
Yes, it is. In the spirit of open source innovation, the model’s weights are released under the permissive Apache 2.0 license. Developers and researchers can freely access and download them from the Hugging Face platform to use in their own projects and applications.
Why is the reproducibility of this model important?
Reproducibility is crucial for building trust and fostering collaboration in the AI community. Because the datasets, training code, and model weights for NousCoder-14B are all publicly available, other researchers can verify the results, understand the methodology, and build upon this work. This transparency accelerates innovation and ensures that advancements are accessible to everyone.