

Democratizing AI through distributed reinforcement learning is no longer a research slogan. Instead, it offers a practical path to building more capable, accessible models. This article explains how community-driven RL, decentralized compute, and shared environments combine.
You will see why small teams can now fine-tune reasoning models with modest resources. However, the shift depends on open RL environments and robust orchestration tools. Prime Intellect and others demonstrate this with lightweight Wordle probes and larger agents.
As a result, developers can iterate faster, because training becomes more distributed and collaborative. Therefore, expect new startups, specialized agents, and novel software products to emerge. This introduction prepares you for the technical sections ahead, where we unpack architectures, tools, and tradeoffs.
We will cover distributed RL frameworks, environment design, and cost-efficient hardware choices. Moreover, we explore community governance, incentives, and safety considerations for open models. Along the way, expect practical examples and hands-on tips you can try.
In short, this piece aims to demystify how distributed reinforcement learning can broaden access. Read on to see how engineers, researchers, and hobbyists can contribute. We balance optimism with realism, because understanding tradeoffs helps teams scale responsibly. Finally, technical diagrams and code snippets will clarify complex parts.
Principles of democratizing AI through distributed reinforcement learning
At its core, democratizing AI through distributed reinforcement learning means lowering barriers to access. It shifts power from a few cloud providers and labs to a broad community. Because compute and environments become modular, many teams can participate. As a result, innovation accelerates and specialization becomes practical.
Key principles
- Openness and modularity. Shared reinforcement learning environments let creators plug new tasks into existing agents.
- Decentralized compute. Workers across machines and regions coordinate to train agents, which reduces reliance on single vendors.
- Incentive alignment. Community contributions gain credits, data, or model improvements, so contributors scale systems together.
- Reproducibility and auditability. Shared environments and logs make training steps transparent and easier to validate.
- Cost efficiency. Distributed workloads use idle resources and cheaper hardware, lowering the effective price of training.
How distributed reinforcement learning enables democratization
Distributed reinforcement learning splits experience collection and policy updates across many nodes. Simple agents run environments locally and send gradients or trajectories to central learners. This design reduces the need for a single massive GPU cluster. Moreover, it allows hobbyist hardware to contribute useful signal. Because environments can be small and composable, teams iterate quickly on task design. Therefore, researchers can explore many ideas without huge budgets.
Practical mechanisms
- Environment marketplaces let developers find and reuse task setups.
- Federated or sharded learners aggregate updates while preserving privacy.
- Lightweight orchestration systems manage synchronization and fault tolerance.
- Community hubs curate testbeds, benchmarks, and rewards for contributors.
Why it matters
This approach expands who can build reasoning models. In turn, it seeds startups, educational projects, and niche agents. For an applied example and further reading see this article on distributed RL approaches: distributed RL approaches. Moreover, this model addresses bottlenecks in open frontier models by widening the pool of builders.
Related keywords include open source AI, reinforcement learning environments, decentralized AI, and INTELLECT-3. Embracing these principles helps teams scale responsibly and innovate faster.
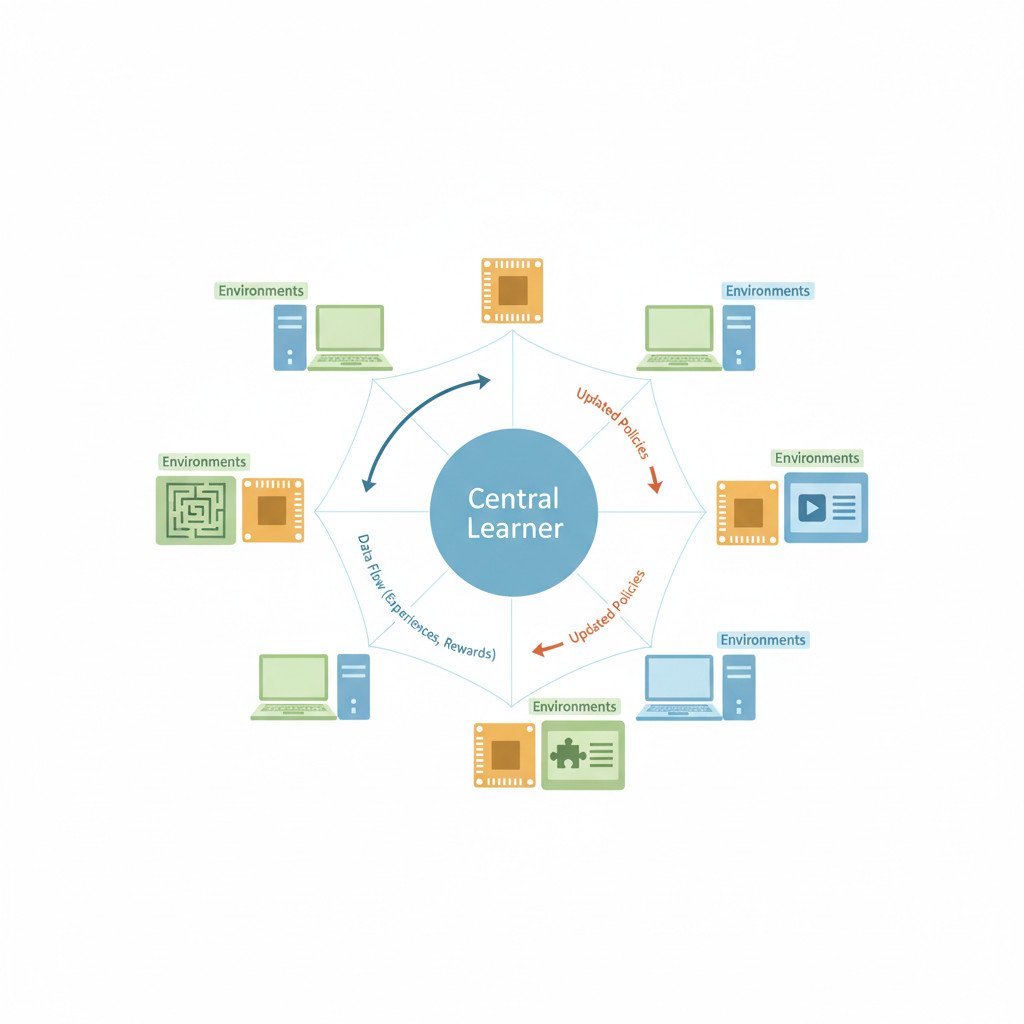
Evidence and case studies: distributed reinforcement learning in action
- Prime Intellect INTELLECT series
- Named entities Vincent Weisser and Will Brown feature in this effort. They built open RL environments and distributed training pipelines. INTELLECT-1 was a 10 billion parameter model trained with distributed hardware. INTELLECT-2 scaled to a larger model using asynchronous, permissionless RL contributors. These releases show that decentralized training can produce competitive reasoning models. For technical details see Prime Intellect’s writeups and community notes: INTELLECT-1 Release and INTELLECT-2 Release. Keywords reinforced include INTELLECT-1, INTELLECT-2, INTELLECT-3, distributed reinforcement learning, and open reinforcement learning environments.
- Wordle environment proof of concept
- Named entity Will Brown created a small Wordle RL environment. The author tested a tiny model and it solved puzzles. This simple experiment underscores how compact environments generate useful learning signals. Therefore, small teams can prototype tasks quickly. Related keywords are Wordle environment, reinforcement learning environments, and hobbyist RL.
- INTELLECT-3 fine-tuning experiments
- Prime Intellect is training INTELLECT-3 using distributed reinforcement learning for fine-tuning. As a result, the group demonstrates practical fine-tuning at scale without centralized clusters. This shows democratization because contributors across hardware tiers contribute trajectories and gradients. Related keywords include democratizing AI through distributed reinforcement learning and decentralized AI.
- Community platforms and environment hubs
- Prime Intellect and allied projects launched environment hubs to share task setups. These hubs let contributors reproduce experiments, audit rollouts, and reuse benchmarks. Consequently, reproducibility improves and audit trails grow. Useful keywords include environment marketplaces, reproducibility, and open source AI.
- Industry context and complementary launches
- DeepSeek introduced a low-cost reasoning model in January 2025, showing cost-effective approaches to reasoning. OpenAI released an open source model in August 2025, which expanded baseline tools for the community. Meta’s Llama updates in 2025 disappointed some researchers, which in turn reinforced interest in open, distributed alternatives. These developments signal that distributed RL fits a wider ecosystem. Keywords here include DeepSeek, OpenAI open source model, Meta Llama, and open frontier models.
- External validation and commentary
- Andrej Karpathy called Prime Intellect’s RL environments “a great effort and idea.” Vincent Weisser warned that environments are a bottleneck to scaling capabilities. Thus, community-built environments address a critical constraint. In turn, they enable more teams to compete in model development.
Together these examples provide practical evidence. They show how distributed reinforcement learning lowers cost, increases participation, and speeds iteration. Therefore, democratizing AI through distributed reinforcement learning moves from theory to proven practice.
| Aspect | Traditional centralized training | Distributed reinforcement learning |
|---|---|---|
| Scalability | Scales by buying larger clusters and GPUs. | Scales horizontally by adding nodes and edge contributors. |
| Accessibility | Requires deep pockets and cloud credits. | Lowers barriers; hobbyist and academic hardware can join. |
| Cost | High capital and operational costs for dedicated clusters. | Uses idle resources and cheaper hardware to reduce cost. |
| Speed | Fast with large clusters, but limited by provisioning time. | Often faster for diverse tasks because of parallel environment workers. |
| Fault tolerance | Single points of failure risk slow recovery. | Resilient; failures are isolated to individual workers. |
| Resource utilization | Underutilized in batch schedules and idle times. | Efficient; leverages intermittent compute and edge devices. |
| Iteration cycle | Long iterations due to costly experiment runs. | Short iterations because small environments and parallel rollouts help. |
| Reproducibility | Harder to reproduce without exact cluster specs. | Easier when environments and logs are shared openly. |
| Governance and openness | Proprietary models and closed datasets dominate. | Encourages open environments, audits, and community governance. |
| Example projects | Large lab models and private clusters. | Prime Intellect INTELLECT series, Wordle RL probes, environment hubs. |
Key takeaways
- Therefore, distributed reinforcement learning reduces cost and broadens participation.
- However, it introduces orchestration and environment quality challenges.
- Because community hubs share tasks, reproducibility and auditability improve.
Challenges and limitations of democratizing AI through distributed reinforcement learning
Distributed reinforcement learning unlocks many opportunities. However, it also introduces real hurdles across operations, engineering, and security. Below we break these down in clear terms with examples and related keywords.
Operational challenges
- Orchestration complexity. Coordinating thousands of workers is hard. For example, synchronizing policy updates across shards creates latency and staleness. As a result, teams need robust orchestration and monitoring tools.
- Environment quality and curation. Community-contributed reinforcement learning environments vary in quality. Therefore, low-quality tasks can bias training or produce brittle agents. Curated testbeds and benchmarks become essential.
- Incentives and governance. Contributors need fair rewards and rules. Otherwise, malicious or low-effort contributions dilute signal. In turn, governance systems must balance openness with quality control.
Technical limitations
- Communication overhead. Distributed setups send trajectories and gradients over networks. This increases bandwidth needs and slows down learning when links are poor. Consequently, edge contributors with limited connectivity add noise.
- Heterogeneous hardware. Nodes differ in CPU, GPU, and memory. As a result, load balancing and reproducibility suffer. Federated or sharded learners can help, but they add engineering cost.
- Debugging and reproducibility. Tracing failures across many machines is time consuming. Moreover, exact experiment replication requires shared environment snapshots and logs. Thus, reproducibility remains an engineering burden.
Security and safety risks
- Data poisoning and adversarial contributions. Open systems risk poisoned trajectories or manipulated environments. For example, a crafted environment can steer policies toward unsafe behavior.
- Privacy leakage. Trajectories may contain sensitive signals. Therefore, teams must use differential privacy or secure aggregation to protect contributors and users.
- Model theft and misuse. Decentralized models can leak weights or checkpoints. In turn, bad actors could extract capabilities or fine-tune harmful behavior.
Practical mitigations
- Use validation sandboxes and automated checks. In addition, apply reputation systems for contributors. Finally, employ secure aggregation and federated learning methods.
Related keywords include open source AI, reinforcement learning environments, decentralized AI, INTELLECT-3, and distributed reinforcement learning. Addressing these limits is essential to scale safely and responsibly.

Future prospects for democratizing AI through distributed reinforcement learning
Distributed reinforcement learning is poised to reshape who builds advanced AI. Over the next few years, expect practical innovations that tackle current limits and open new use cases. Startups, academic labs, and hobbyists will drive many of these changes because tools become cheaper and more modular.
Key anticipated innovations
- Better orchestration layers
- Lightweight schedulers will reduce synchronization overhead. As a result, networks with intermittent nodes will train more reliably.
- Standardized environment catalogs
- Curated reinforcement learning environments will improve reproducibility. Therefore, teams can compare agents fairly and iterate faster.
- Secure aggregation and privacy primitives
- Federated learning tools and secure aggregation will mitigate data leakage. In turn, contributors can share trajectories safely.
- Heterogeneous hardware stacks and compilers
- New compilers and runtimes will optimize varied chips. Consequently, contributors can use consumer GPUs, TPUs, and edge accelerators.
- Incentive and reputation systems
- Tokenized or credit-based rewards will align contributors. Moreover, reputation systems will filter low-quality environments.
Industry impact and new business models
- Niche agents and vertical startups will proliferate. Because training costs drop, teams will build specialized agents for healthcare, finance, and education.
- Cloud providers will offer hybrid marketplaces. As a result, they will combine managed learners with community environment hubs.
- Academic research will accelerate. Open source AI tools and shared benchmarks will lower experimental friction.
How trends address current challenges
- Improved monitoring and sandboxing reduce security risk. Thus, teams can validate contributions before merging them.
- Compression and gradient sparsification lower bandwidth. Therefore, edge contributors become more useful.
- Standard governance templates balance openness with safety. As a result, projects can scale without losing auditability.
Related keywords include open source AI, reinforcement learning environments, decentralized AI, and INTELLECT-3. Overall, democratizing AI through distributed reinforcement learning looks achievable. However, teams must pair optimism with careful engineering and governance to scale responsibly.
Practical implementation tips for businesses adopting distributed reinforcement learning
-
Start with clear goals and small pilots
- Define a narrow task and success metrics before wide rollout. For example, prototype a customer-support agent in a contained environment.
- Because experiments remain cheap, iterate rapidly and stop unpromising directions early.
-
Choose the right technology stack
- Use lightweight orchestrators such as Ray or custom schedulers for asynchronous rollouts.
- Consider runtimes that support heterogeneous hardware to leverage consumer GPUs and edge accelerators.
- In addition, pick frameworks that export reproducible environment snapshots and logs.
-
Design curated reinforcement learning environments
- Build small, high-quality environments that reflect real tasks. Therefore, training yields robust signals.
- Also create validation sandboxes to check agent behavior before merging updates.
-
Implement secure aggregation and privacy primitives
- Apply secure aggregation or federated learning to protect contributor data.
- Finally, use differential privacy and access controls for any sensitive trajectories.
-
Create contributor incentives and governance
- Reward high-quality environment authors and workers with credits or reputation points.
- Moreover, enforce contribution checks and automated tests to maintain dataset quality.
-
Monitor, audit, and reproduce
- Log trajectories, model checkpoints, and environment versions for audits.
- Use automated monitors to detect drift, poisoning, or adversarial signals early.
-
Operationalize cost and resource planning
- Mix spot compute, idle resources, and cloud bursts to lower costs.
- Because communication is expensive, compress gradients and prioritize sparse updates.
Related keywords include democratizing AI through distributed reinforcement learning, open source AI, reinforcement learning environments, decentralized AI, and INTELLECT-3.
Conclusion
Democratizing AI through distributed reinforcement learning can widen access to powerful models. Over this article we explained core principles, practical mechanisms, and real-world successes. We also reviewed operational costs, security risks, and governance needs.
However, the shift from centralized labs to community-driven training is already underway. Prime Intellect’s INTELLECT series and small environment probes prove distributed approaches work. Moreover, community hubs and curated testbeds reduce reproducibility gaps. Therefore, teams can iterate faster while keeping costs lower.
For businesses, start small with pilots and adopt secure aggregation and validation sandboxes. In addition, choose orchestration tools that support heterogeneous hardware and compressed updates. As a result, teams will build niche agents, vertical startups, and safer open models.
EMP0 (Employee Number Zero, LLC) helps organizations apply these ideas. EMP0 focuses on AI and automation solutions for sales and marketing. Visit their website for services and case studies: EMP0 Services. Read more on their blog at EMP0 Blog. You can also explore their n8n automations at n8n Automations. Follow their updates by name on Twitter at @Emp0_com.
In short, distributed reinforcement learning offers a practical path to broaden participation. With careful engineering and governance, democratizing AI through distributed reinforcement learning can become both responsible and scalable.