

AI models and developer tooling: Nemotron 3 and chat-first tools reshaping LLM workflows
AI models and developer tooling converge in Nemotron 3, a leap that accelerates large language model performance and usability. Nemotron 3 Nano, Super, and Ultra unlock sparse Mixture of Experts scaling, while improving throughput and efficiency. Moreover, the Nano variant routes a tiny subset of experts per token, which saves compute cost. As a result, Nano achieves about four times higher token throughput than its predecessor. Super and Ultra add LatentMoE and multi-token prediction heads, therefore supporting massive context windows up to one million tokens.
Developers benefit from open weights, NVFP4 training efficiency, and Hugging Face model availability for experimentation. Furthermore, chat-first developer tooling transforms workflows by embedding conversational APIs, observability, and microservice deployments. These tools help teams iterate faster, because they streamline prompt engineering, testing, and developer handoffs. Together, Nemotron 3 and chat-first toolchains reduce latency, improve debugging, and accelerate production-ready model delivery.
Therefore, organizations can build larger, more context-aware assistants while lowering cloud and on-prem compute bills. In short, Nemotron 3 signals a shift in AI models and developer tooling toward open, efficient, and chat-native development. This revolution reshapes prompt tooling, observability, and deployment pipelines for modern AI teams.
Nemotron 3 Variants for AI models and developer tooling
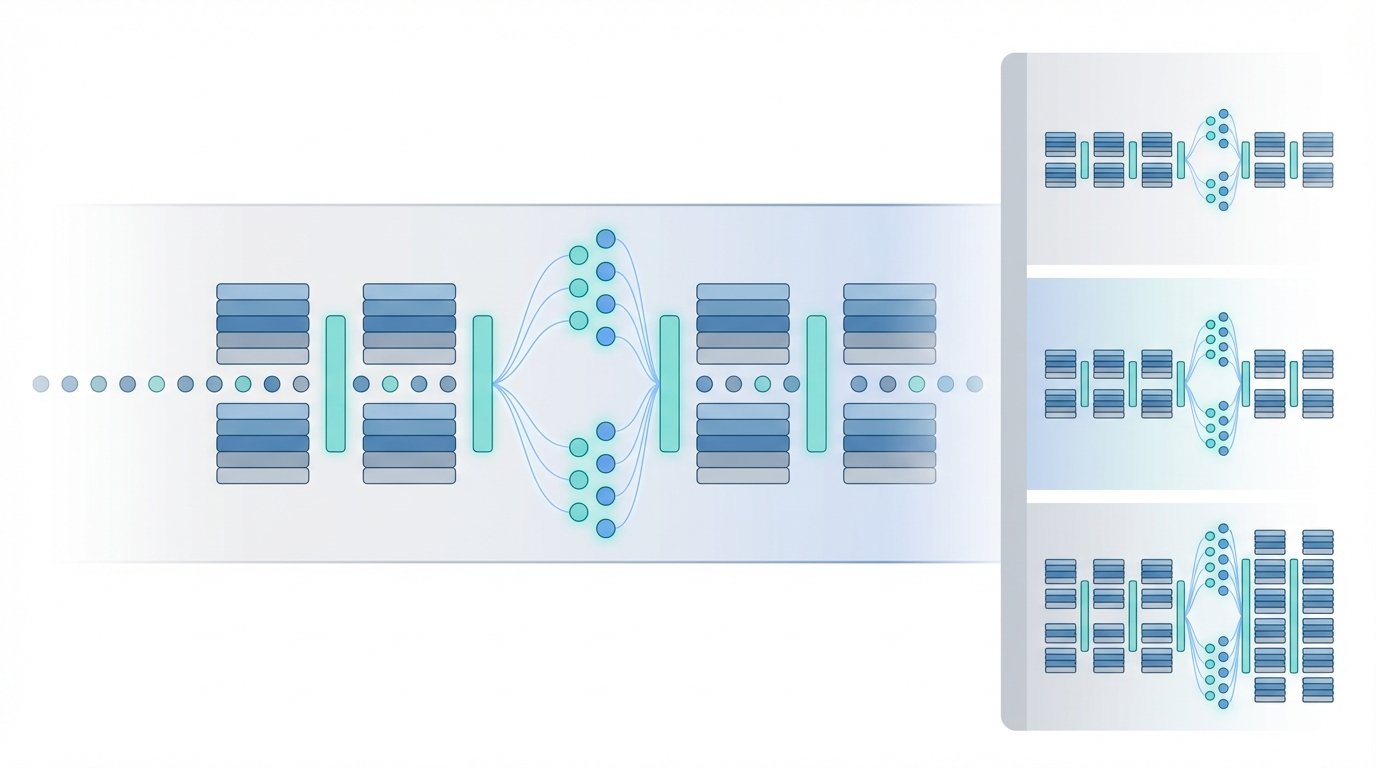
Nemotron 3 ships three variants tuned for different scale and cost profiles. Each model balances dense and sparse compute to raise throughput and lower inference cost. Moreover, the family embraces Mixture of Experts and Mamba Transformer building blocks to scale sparsely.
Nemotron 3 Nano
- Parameters: about 31.6 billion total.
- Active parameters per token: roughly 3.2 billion per forward pass, 3.6 billion including embeddings.
- Sparse routing: selects a small subset of experts per token, for example six of 128 experts.
- Architecture: interleaved Mamba 2 blocks, attention blocks, and MoE blocks with sparse experts.
- Throughput: delivers about four times the token throughput of Nemotron 2 Nano.
- Data and availability: trained on Nemotron Common Crawl v2.1, Nemotron CC Code, and other datasets.
Nemotron 3 Super
- Parameters: around 100 billion.
- Active parameters per token: up to 10 billion.
- Innovations: adds LatentMoE to enable more experts at similar compute cost.
- Output: supports multi-token prediction with multiple output heads.
- Precision: trained mostly in NVFP4 4-bit precision to save memory.
Nemotron 3 Ultra
- Parameters: roughly 500 billion.
- Active parameters per token: up to 50 billion.
- Scale features: LatentMoE and expanded expert pools support high-capacity routing.
- Use cases: best for massive context understanding and long-form generation.
Common features and developer impact
All models support context windows up to one million tokens and trained on about 25 trillion tokens. As a result, developers gain long-context reasoning and cost-efficient scaling. For details about open weights and community tools see Nemotron 3 Open Source AI Models. For notes on how investments shift marketplaces try AI Investments 2026. Also read why teams should balance AI work with developer roles at AI Not to Replace Junior Devs.
How Nemotron 3 Improves Developer Productivity and Workflows
Nemotron 3 changes developer workflows by pairing high-quality models with chat-first tooling. As a result, teams can iterate faster and deliver features sooner. Developers gain from higher token throughput, long context windows, and open model weights that simplify experimentation.
Key productivity wins
- Faster iteration because Nemotron 3 Nano offers about four times the token throughput of Nemotron 2 Nano. This speeds local testing and reduces cloud costs.
- Long-context debugging because all Nemotron 3 models support up to one million token windows. Therefore, developers can trace long conversations and document histories.
- Easier experimentation because open weights on Hugging Face let engineers adapt and fine-tune models on real datasets. See the Nano weights at model access and examples.
- Efficient deployment since Super and Ultra are trained in NVFP4 4-bit precision. Consequently, teams use less memory and scale inference more cheaply.
Chat-first tooling and NVIDIA microservices
- Conversational APIs let developers embed chat interfaces directly into apps. For example, microservices in NVIDIA NIM simplify model hosting and scaling. Learn more at this documentation.
- Observability and tracing become natural because toolchains capture token-level metrics and routing decisions. As a result, teams debug prompt drift and hallucinations faster.
Practical examples
- A product team prototypes a context-aware assistant. They use the one million token window to maintain session state over long calls.
- A research engineer fine-tunes Nano locally. Then they push the weights to a staging service on NIM for load testing.
Together, Nemotron 3 and chat-first developer tooling improve developer velocity, reduce infrastructure cost, and make production-ready LLMs easier to operate. For technical background and datasets, review NVIDIA’s Nemotron blog at this blog post.
Comparison: Nemotron 3 Nano, Super, Ultra — AI models and developer tooling
This quick table summarizes core specs and strengths of each Nemotron 3 variant. It helps engineers choose the right model for testing, fine tuning, or production. Moreover, the table highlights active parameters, routing, and special features.
| Attribute | Nano | Super | Ultra |
|---|---|---|---|
| Parameter count | ~31.6 billion | ~100 billion | ~500 billion |
| Active token parameters | ~3.2 billion per forward pass (3.6B incl. embeddings) | up to 10 billion | up to 50 billion |
| Token throughput | ~4x Nemotron 2 Nano | optimized for capacity and scaling | optimized for highest capacity |
| Context window | up to 1,000,000 tokens | up to 1,000,000 tokens | up to 1,000,000 tokens |
| Routing and experts | sparse routing selects ~6 of 128 experts per token | LatentMoE for more experts at similar compute cost | LatentMoE with expanded expert pools |
| Specialized features | interleaved Mamba 2 blocks, attention, MoE blocks | LatentMoE, multi-token prediction heads | LatentMoE, multi-token heads, massive routing |
Conclusion: Nemotron 3 and the future of AI models and developer tooling
NVIDIA Nemotron 3 marks a turning point for AI models and developer tooling. Its sparse Mixture of Experts design, massive context windows, and NVFP4 efficiency enable larger, faster, and more cost effective LLMs. Therefore, teams can move from prototype to production faster. As a result, developers gain richer context handling, lower inference costs, and clearer debugging signals.
The practical impact is large and immediate. For example, higher token throughput shortens iteration cycles. Open weights on community hubs accelerate experimentation and fine tuning. NVIDIA microservices make deployment repeatable and scalable. Furthermore, LatentMoE and multi token heads let Super and Ultra target complex reasoning tasks with minimal extra compute.
For businesses, this means smarter assistants and more capable automation. Because Nemotron 3 is open and chat native, companies can embed long lived memory, agent orchestration, and branded experiences. Consequently, development teams ship reliable conversational features sooner and with less cloud spend.
EMP0 applies these advances to growth and automation. EMP0 uses AI powered growth systems and brand trained AI workers to multiply client revenue through automation, personalization, and modern tooling. Explore EMP0 to integrate AI into business operations and scale results. Website: Blog: Twitter/X: Medium: n8n
Frequently Asked Questions (FAQs)
What is Nemotron 3 and why does it matter for AI models and developer tooling?
Nemotron 3 is an open family of models from NVIDIA that includes Nano, Super, and Ultra. It matters because it combines dense and sparse techniques, such as Mixture of Experts and Mamba Transformer blocks, to deliver higher throughput and larger context windows. As a result, developers can build more context aware applications, iterate faster, and lower inference costs.
How big are the Nemotron 3 models and what are their active token parameters?
The Nano model is roughly 31.6 billion parameters with about 3.2 billion active per forward pass (3.6 billion including embeddings). Super is around 100 billion with up to 10 billion active per token. Ultra sits near 500 billion parameters with up to 50 billion active per token.
Can Nemotron 3 handle long conversations or documents?
Yes. All Nemotron 3 variants support context windows up to one million tokens. Therefore, they can maintain long conversation history, analyze extended documents, and handle multi document workflows without frequent context truncation.
What practical developer tooling benefits come with Nemotron 3?
Key benefits include higher token throughput for faster testing, open weights on Hugging Face for experimentation, NVFP4 training and inference efficiency for lower memory usage, and NVIDIA NIM microservices for repeatable deployment. For model access and examples see Hugging Face and for NIM microservices see NVIDIA Documentation.
How will Nemotron 3 change AI engineering and business outcomes?
Nemotron 3 enables richer assistants, better document understanding, and cost efficient scaling. Because the models are open and chat native, organizations can integrate branded AI workers and agent orchestration into workflows. This shortens time to value and supports new automation and personalization capabilities.