

Nemotron Speech ASR: The Future of Real Time Voice AI
Have you ever felt the frustration of talking to a voice assistant that lags, misunderstands, or takes too long to respond? That delay can make any interaction feel unnatural and inefficient. The key to truly seamless voice applications lies in speed and accuracy. This is precisely where new advancements in artificial intelligence are making a significant impact. As a result, developers are now equipped with powerful tools to create the next generation of voice agents.
Introducing Nemotron Speech ASR, a state of the art model designed to power low latency voice interactions. Developed by NVIDIA, this technology provides the foundation for building highly responsive voice agents that can understand and reply in near real time. Because of its advanced architecture, Nemotron Speech ASR dramatically reduces the processing delay that plagues many existing systems. This allows for conversations with AI that feel more like talking to a human.
Furthermore, what makes this model truly revolutionary is its accessibility. Nemotron Speech ASR is available as an open source project, providing developers and researchers worldwide with access to its powerful capabilities. This open approach fosters innovation and allows the community to build upon a solid foundation of high performance speech recognition. In this article, we will explore the technology behind this model, its impressive performance benchmarks, and how you can start using it to build your own advanced voice applications.
Key Features of Nemotron Speech ASR
The remarkable performance of Nemotron Speech ASR stems from its sophisticated and highly optimized architecture. This model is designed from the ground up to minimize latency while maintaining high accuracy, making it ideal for real time voice applications. At its core, the system is built on a powerful 600 million parameter model that effectively balances complexity and speed. This allows it to handle complex language patterns without introducing significant delays.
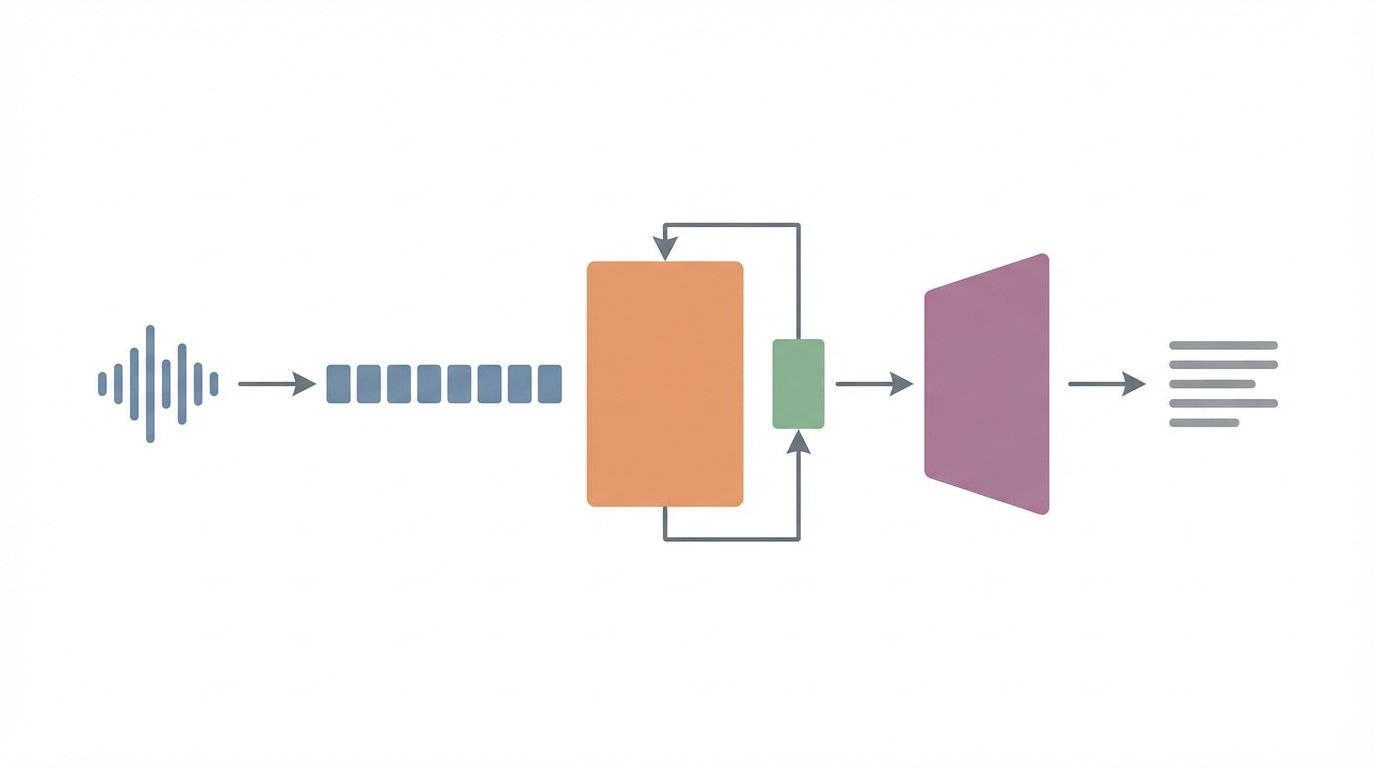
The architecture relies on two primary components: a specialized encoder and a corresponding decoder. The encoder uses a cache aware FastConformer design with 24 layers. This structure is crucial for streaming audio because it keeps a cache of previous audio states. As a result, the model avoids recomputing context for every new piece of audio, saving valuable processing time. Furthermore, the encoder employs an aggressive 8x convolutional downsampling technique. This process significantly reduces the number of time steps the model needs to analyze, directly contributing to its low latency performance.
To manage incoming audio efficiently, the Nemotron Speech ASR model processes sound in small segments or chunks. This approach allows for near instantaneous transcription as a person speaks. Developers can choose from four distinct chunk configurations to balance speed and context:
- Approximately 80 milliseconds
- Approximately 160 milliseconds
- Approximately 560 milliseconds
- Approximately 1.12 seconds
Smaller chunks deliver faster responses, while larger ones provide the model with more context, which can improve transcription accuracy. This flexibility is enhanced by the att_context_size parameter. This feature lets developers control the attention context at inference time without needing to retrain the model. Consequently, they can fine tune the balance between latency and accuracy to fit the specific needs of their application. Finally, an RNNT decoder works in tandem with the encoder to generate text as the audio streams in, completing the low latency pipeline.
Performance Metrics and Benchmark Data for Nemotron Speech ASR
The true value of any Automatic Speech Recognition system lies in its performance under real world conditions. For Nemotron Speech ASR, the key metrics are accuracy, concurrency, and latency. These factors determine its suitability for demanding applications like voice agents and customer service bots. Consequently, rigorous testing across various hardware platforms reveals the model’s impressive capabilities.
Accuracy is primarily measured using the Word Error Rate (WER), which calculates the percentage of incorrectly transcribed words. The performance of Nemotron Speech ASR improves as it receives more audio context. For instance, with a 160 millisecond chunk, the model achieves an average WER of approximately 7.84% across OpenASR datasets. When the chunk size increases to 560 milliseconds, the error rate drops to around 7.22%. Furthermore, with a 1.12 second chunk, the WER is further reduced to about 7.16%, demonstrating a clear trade off between latency and accuracy.
Concurrency, or the ability to handle multiple simultaneous audio streams, is critical for scalable services. On powerful hardware like the NVIDIA H100 GPU, the model can process 560 concurrent streams using a 320 millisecond chunk size. This represents a threefold improvement over baseline models. Similarly, the RTX A5000 shows more than a fivefold increase in concurrency, while the DGX B200 offers up to a twofold improvement. These figures highlight the model’s efficiency and its capacity to power large scale applications.
Finally, latency stability ensures a smooth user experience. In tests with 127 concurrent clients, the system maintained a median end to end delay of just 182 milliseconds in the 560 millisecond mode. Most importantly, this performance remained stable without any drift, ensuring predictable response times even under heavy load.
| Hardware Platform | Metric | Value | Chunk Size |
|---|---|---|---|
| N/A | Word Error Rate (WER) | ~7.84% | 160 ms |
| N/A | Word Error Rate (WER) | ~7.22% | 560 ms |
| N/A | Word Error Rate (WER) | ~7.16% | 1.12 s |
| NVIDIA H100 | Concurrency | 560 streams | 320 ms |
| NVIDIA RTX A5000 | Concurrency | >5x improvement | N/A |
| NVIDIA DGX B200 | Concurrency | Up to 2x improvement | N/A |
| N/A | Latency Stability | 182 ms median delay (127 concurrent clients) | 560 ms |
Nemotron Speech ASR Performance Overview
| GPU Model / Metric | Chunk Size | Max Concurrency | Word Error Rate (WER) | Median Latency |
|---|---|---|---|---|
| NVIDIA H100 | 320 ms | 560 streams | Not Specified | Not Specified |
| NVIDIA RTX A5000 | Not Specified | >5x Improvement | Not Specified | Not Specified |
| NVIDIA DGX B200 | Not Specified | Up to 2x Improvement | Not Specified | Not Specified |
| General Accuracy | 160 ms | Not Applicable | ~7.84% | Not Applicable |
| General Accuracy | 560 ms | Not Applicable | ~7.22% | Not Applicable |
| General Accuracy | 1.12 s | Not Applicable | ~7.16% | Not Applicable |
| Latency Stability | 560 ms | 127 Clients | Not Applicable | 182 ms |
Conclusion: Revolutionizing Voice AI with Open Source Innovation
Nemotron Speech ASR represents a major leap forward in the field of automated speech recognition. By delivering both low latency and high accuracy, it addresses the core challenges that have limited the potential of voice agents. This technology paves the way for more natural, responsive, and effective human computer interactions. Because NVIDIA has made this powerful tool open source, developers and businesses now have unprecedented access to state of the art ASR capabilities. This will undoubtedly accelerate innovation and lead to a new generation of sophisticated voice powered applications.
For businesses, leveraging advanced AI like Nemotron Speech ASR is no longer a futuristic concept but a present day necessity for growth. The ability to deploy intelligent automation can transform sales, marketing, and customer support. This is where a partner like EMP0 becomes invaluable. As a leader in AI driven automation, EMP0 specializes in creating full stack, brand trained AI systems that integrate seamlessly into your operations. These systems are designed to multiply revenue by deploying secure, AI powered growth solutions directly within your own infrastructure.
To learn more about how custom AI solutions can elevate your business, explore our resources and connect with our work.
Blog: articles.emp0.com
Frequently Asked Questions (FAQs)
What is Nemotron Speech ASR?
Nemotron Speech ASR is an advanced automatic speech recognition model developed by NVIDIA. It is specifically designed for applications that require low latency, real time transcription. Because of its specialized architecture, the model can quickly and accurately convert spoken language into text, making it ideal for interactive voice agents and other demanding use cases.
How does Nemotron Speech ASR differ from traditional ASR systems?
Traditional streaming ASR systems often recompute overlapping segments of audio, which creates unnecessary processing overhead and increases latency. In contrast, Nemotron Speech ASR uses a cache aware encoder. This system intelligently stores the states of previously processed audio chunks. As a result, it avoids redundant calculations, leading to significantly faster performance and a more efficient use of resources.
How does the model achieve such low latency?
The low latency of Nemotron Speech ASR is the result of several key architectural innovations. Firstly, its cache aware FastConformer encoder minimizes repetitive processing. Secondly, it uses an aggressive 8x convolutional downsampling method to reduce the amount of data that needs to be analyzed. Finally, its efficient processing of small audio chunks allows it to transcribe speech in near real time.
Is Nemotron Speech ASR available for public use?
Yes, Nemotron Speech ASR is an open source model. NVIDIA has released it under a permissive open model license, which includes open weights and detailed training information. Consequently, developers and researchers can freely access the model on platforms like Hugging Face, allowing for widespread adoption and community driven innovation.
What are some potential business applications for this technology?
The capabilities of this streaming ASR make it suitable for a wide range of business applications. For example, companies can build highly responsive voice agents for customer support centers to handle queries instantly. Other uses include real time transcription services for meetings and broadcasts, advanced in car voice assistants, and interactive voice response systems that feel more natural and conversational.