

KV caching: How to dramatically speed up token generation in LLMs
KV caching is a simple but powerful trick that reuses keys and values from prior tokens to avoid repeated attention work. In short, KV caching stores keys and values for earlier tokens and reuses them, which dramatically reduces redundant computation when generating long sequences. Because KV caching prevents the model from recomputing attention over all past tokens at every step, it speeds up token generation and improves inference latency for real applications.
Why this matters: inference speed directly affects product responsiveness, user experience, and cloud costs. For example, without KV caching, generation time grows quadratically as the sequence length increases. However, with KV caching, generation time grows nearly linearly, so long outputs remain practical. As a result, real time applications like chatbots, assistants, and streaming systems feel far more responsive.
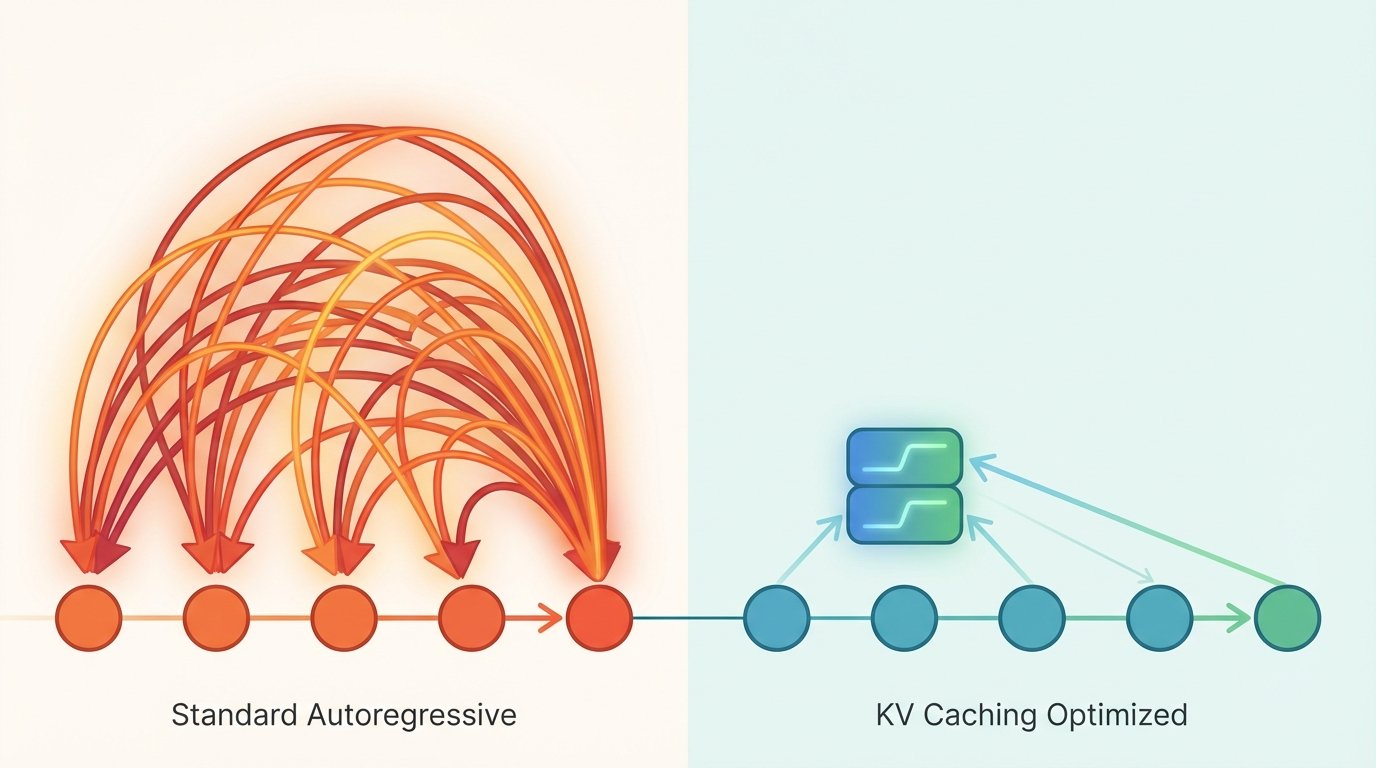
Visual idea for an image: show a simple side by side comparison. On the left, draw many arrows from each new token back to all prior tokens to show repeated attention. On the right, show a short stack labeled K and V that persists, with new tokens only attending forward. This visual highlights speed up, lower computation, and extra cache memory usage.
Related keywords to watch for include inference speed, token generation, autoregressive generation, attention, and cache memory.
KV caching in autoregressive generation
Autoregressive models generate text one token at a time. At each step, the model computes attention between the new token and all prior tokens. KV caching stores the already computed keys and values so the model does not recompute them for every new token. As a result, KV caching speeds up token generation and improves inference speed for long sequences.
How K, V and Q interact with attention
The attention block uses three components. Query Q represents the current token. Keys K and values V represent prior tokens. The model computes attention scores as softmax(Q K^T / sqrt(d)) and then multiplies those scores by V. Because scores depend on K and V, recomputing their projections for every step is expensive. With KV caching, the model reuses stored K and V tensors from past steps. Therefore, only the new token’s projections need computation.
Key technical points
-
Computation without KV caching
- Each generation step projects all tokens into K and V again. Because of that, cost grows roughly with the square of sequence length. In other words, computation scales quadratically and slows inference dramatically.
-
Computation with KV caching
- The model appends new K and V to the cache. Consequently, the model only projects the newest token each step. This change makes overall work grow nearly linearly with sequence length.
Practical trade offs and notes
- KV caching reduces redundant compute but increases memory usage to store past key and value tensors. Therefore, you trade memory for speed.
- Libraries implement this as
past_key_values. For example see Hugging Face documentation at Hugging Face documentation for implementation details. - For foundational context on attention mechanics see the original paper at Attention is All You Need.
Related keywords: inference speed, token generation, attention, autoregressive generation, cache memory.
Empirical evidence: KV caching performance
- Key result: With KV caching enabled, generating 1000 tokens takes around 21.7 seconds.
- Baseline: Without KV caching, generating 1000 tokens exceeds 107 seconds, nearly a 5× slowdown.
- Therefore inference speed improves roughly fivefold because KV caching eliminates redundant attention recomputation.
- Experiment details: used gpt2-medium. Reference: Hugging Face GPT-2 Medium
- Implementation note: models used transformers AutoModelForCausalLM and AutoTokenizer. See implementation: Transformers Implementation
- Memory tradeoff: KV caching reduces computation and increases memory to store past keys and values.
- Quote from Arham Islam: “KV caching is an optimization technique used during text generation in large language models.”
- MarkTechPost summary: “This experiment highlights why KV caching is essential for efficient, real-world deployment.”
- Background: attention mechanics at Attention Mechanics Paper
- Per token latency: With KV caching ~0.0217 seconds per token; without caching ~0.107 seconds per token.
- As a result, real-time systems see lower latency and lower compute costs.
- Cache size grows with sequence length, hidden dimension, and number of layers.
KV caching performance comparison
Below is a concise comparison of key metrics for token generation with and without KV caching. The table highlights generation time, computation complexity, memory usage, and overall inference efficiency for clarity.
| Feature | KV caching enabled | KV caching disabled |
|---|---|---|
| Generation time (1000 tokens) | ~21.7 seconds | >107 seconds |
| Per-token latency | ~0.0217 s/token | ~0.107 s/token |
| Computation complexity | Nearly linear growth O(n) | Quadratic growth O(n2) |
| Memory usage | Higher due to stored K and V tensors | Lower runtime memory, no cache |
| Overall inference efficiency | High — better inference speed and lower compute cost | Low — slower token generation and higher compute waste |
| Practical impact | Faster real-time responses and lower cloud costs | Slower responses and higher latency costs |
This table uses related keywords such as KV caching, inference speed, token generation, and attention to aid SEO and reader clarity.
Conclusion: KV caching as a deployment multiplier
KV caching is a small change with large effects. It removes redundant attention work by reusing past keys and values. As a result, inference speed improves dramatically and token generation becomes practical for long sequences. Therefore systems that need low latency and high throughput benefit directly.
In production, this matters for responsiveness and cost. For example, chat systems, agents, and streaming applications see lower latency and reduced compute spend. At the same time, engineers trade extra memory for much faster generation. This tradeoff is often worth it because real users expect near-instant replies.
EMP0 helps organizations apply these optimizations safely under their own infrastructure. EMP0 provides AI solutions and automation that leverage techniques like KV caching. As a result, teams can scale inference, cut latency, and control costs while keeping data on premises.
Take the next step: evaluate KV caching in your deployment and explore how EMP0 can help implement efficient, secure inference. Learn more at EMP0 website.
Frequently Asked Questions (FAQs)
What is KV caching and how does it work?
KV caching stores past keys and values produced by attention layers. When the model generates a new token, it computes the query for the new token only. Then it reuses cached keys and values to compute attention scores. As a result, the model avoids reprojecting all prior tokens. This reduces redundant computation and speeds up token generation.
Why does KV caching improve inference speed so much?
Without KV caching, attention recomputes projections for every prior token at each step, which causes quadratic growth. However with KV caching, the model appends new keys and values and reuses earlier projections. Therefore work grows nearly linearly as sequence length increases. For example, generating 1000 tokens takes about 21.7 seconds with KV caching, whereas it exceeds 107 seconds without it. As a result, KV caching can deliver roughly a fivefold improvement in inference speed.
What are the memory and technical tradeoffs I should know?
KV caching increases memory because you store K and V for each layer and token. The cache size grows with sequence length, hidden dimension, and number of layers. However the speed gains often justify this memory cost for real-time systems. If memory is limited, you can use shorter context windows, token pruning, or mixed precision to reduce footprint.
How do I enable KV caching in practice with transformers and gpt2-medium?
Most libraries expose a use_cache or past_key_values flag. For example use AutoModelForCausalLM from transformers and enable use_cache during generation. Then the model returns past_key_values that you pass back on the next step. This pattern reduces per-step work and speeds up autoregressive generation.
Which applications benefit most from KV caching and what deployment tips help?
Chatbots, streaming APIs, interactive agents, and long-form generation benefit most. To deploy safely, monitor memory usage, tune batch sizes, and prefer streaming where possible. Finally measure per-token latency and cost so you can balance memory and inference speed effectively.